I like to make assumptions, so my first assumption is that you have been in the space of AI for some time now or you're an enthusiast who has heard about some of the amazing feats that Reinforcement learning has helped AI researchers to achieve.
You might have looked around for some introductory guide to reinforcement learning and seen articles with so much maths, this post is different, I won't intimidate you with so many equations, my goal here is to give you a high-level intuition of RL with a lot of the intimidating maths left out.
So what is Reinforcement learning of RL?
Reinforcement learning (RL) is a trial and error form of learning in which an agent acting in a given environment learns to take optimal actions at every state it encounters in such an environment with the ultimate goal to increase/maximize a numerical reward function.
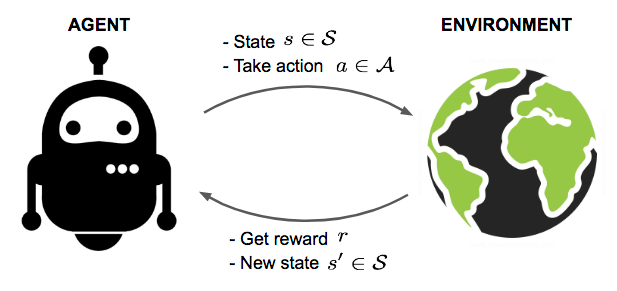 Adapted from Lilian Weng (https://lilianweng.github.io)
Adapted from Lilian Weng (https://lilianweng.github.io)
An agent is an actor in an environment with a clear goal to maximize a numerical reward function.
There are four 4 major properties of an RL problem, namely
- - The policy
- - The reward signal
- - The value function
- - A model (which is optional)
Let’s define some of these properties and explain how they relate to our agent.
The Policy $ \pi(s_t, a_t) $
The policy is simply a function that maps states to actions, a policy directs the agent on the action to take at every given state the agent encounters in the environment, in an RL setting the agent, tries to achieve the optimal policy $ \pi^{*} $ which gives the optimal action at every time step.
The Reward Signal $ (r) $
The reward is a numerical value that the agent receives either at every time step. The reward signals the agent about the "goodness" or "badness" of the actions they've taken and our agent's objective is to maximize the reward. It is also an instant signal meaning that you get a reward at every time step.
Value Function
There are two types of value functions, namely;
State value function - $ V_{\pi }(s_t) $
Action value function - $ Q_{\pi }(s_t, a_t) $
A value function tells the agent how good their current state is (the value of their current state), every particular state in the environment has a certain value and this is equal to the mean or expected return the agent will get from that state onward.
The return $ G_t $ is simply a sum of the discounted future rewards.
$$ G_{t}=R_{t+1}+\gamma R_{t+2}+\cdots=\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} $$
Unlike a reward signal which an agent receives immediately, a value function helps the agent to decide what is good in the long run. The reward an agent might get from a current state might be low in magnitude, but if the sequence of states leading the present one has higher rewards then we can say it has a high value because of the long-term "goodness" from that state onwards.
The equation for the state value function simply tells us that $ V_{\pi}(S) $ is the expected or mean return from that state while following a policy $ \pi $.
$$ V_{\pi}(S) = E_{\pi}\left [ G_{t} \right | S_{t} = s] $$
The action-value function takes into consideration the action $ a_t $ at every timestep as part input to the function, $ Q_{\pi}(s_t, a_t) $ can be simply said to be the expected return from starting at a state $ s_{t} $ and taking action $ a_t $ while following a policy $ \pi $ .
$$Q_{\pi}(s,a) = E_{\pi}\left [ G_{t} \right | S_{t} = s , A_{t} = a] $$
Model
A model is optional in a reinforcement learning problem. A model contains prior information about the environment, it tells the agent what to expect from the environment, the agent can then make decisions based on this model of the environment but it is key to note that one doesn't always have a model of the environment. Also, the model could be a limiting factor because the agent turns out to be as good as the model, therefore if the model of the environment is poor the agent will perform poorly in the real environment.
Now, consider a freshman on a university campus;
The freshman is our agent and the university campus is our environment. we can define some other parameters for our agent.
Let’s make an assumption that the reward function our agent is trying to maximize is the CGPA, I say this because we could be interested in maximizing other rewards we get from a school campus like networking, fun, etc. but since our agent is supposed to have a clear and specific goal, we can focus on the CGPA objective.
A state is any activity our agent engages in at any time step in the environment, it could be sleeping, being in class, reading, partying, etc.
A model here would be any foreknowledge we have about how things move in the school, this could be orientation, advice, etc. basically anything that helps our agent with planning.
Since our agents' goal is to maximize the CGPA, states like, studying, reading, or doing more academic work will have a higher value but fewer rewards (because they don't bring instant gratification/reward).
Exploration Vs. Exploitation
This is another big part of reinforcement learning problems, the explore-exploit dilemma asks the question: When an agent finds a state that generates high rewards should it keep visiting that state (exploiting), or should it keep searching for states with even higher rewards (exploring)?
This is what brings about the "exploration-exploitation trade-off"
The dilemma sounds simple but it can be very complex when we start talking about ways to balance the two, since our agents’ goal is to maximize rewards, we want to always know when it's best to stop exploring and start exploiting and vise-versa.
We can imagine a situation where our agent reads very well during the day and wants to explore the option of nighttime reading to see if it gives even higher rewards. Another case is where our agent might want to find out if reading the whole school work on their own gives greater rewards than attending lectures. These are some of the reasons why there is a need for exploration.
One of the very common ways in which we handle this trade-off is using the $ \epsilon-greedy $ approach, but I won't talk about that in this article.
Now that we have a high-level intuition of reinforcement learning, in a later article I'll dive deep into some of the core maths of RL.
Powered by Froala Editor