If you’re reading this on a smartphone or PC, then there’s a 99% chance that you’ve used a machine learning-powered app or service in the past. Real-time generated video captions, auto-tagging of images, auto-correct, text and image generation, etc. are some of the mainstream applications of machine learning.
But how do you build machine learning (ML) systems and scale them? These are the types of problems that machine learning engineers seek to solve every day. Machine learning engineers serve machine learning models and integrate them with apps and services.
I like to make assumptions about readers. So I assume that if you’re reading this, you’re trying to learn about machine learning engineering or you’re just curious about how these systems are built. One of the big questions you might want answered is how machine learning applications are built. If that’s right, then I’ve got your back!
In this article, they talked about how to maintain good machine-learning goals. The four goals of any machine learning operation are that it should be reproducible, accountable, collaborative, and continuous. What this means is that for any ML project:
- 1. You want the results to be consistent when other people try to use your parameters and datasets.
- 2. You want to create a process where sharing your data and models with other people in your team or organization is easy.
- 3. You want to create workflows that make it easy to debug or catch potential errors.
- 4. You want to make it easy for yourself and others to continue working with or improving the model/workflow without breaking stuff.
I’ve created a 5-item pack of things to know as a machine learning engineer. You should not think of it as a sequential list but as an itinerary of skills to add to your toolbox.
1) Learn a programming language
Learning a programming language gives you the ability to write programs, automation scripts, pipelines, and workflows. There are a lot of debates in the ML community about the best language to learn. People suggest languages like R, Python, Julia, etc.
But one that has always dominated those conversations is Python. The reason for this is because of its ecosystem and the large number of third-party libraries. This makes Python such a joy to use. For most problems you would encounter, there is already a library or related solution that you can use. The beauty of using Python is that it’s not just a data science language like R. It can be used to build systems, write APIs, and websites, interact with databases, etc. Learning Python pretty much sets you up for success in domains outside of machine learning.
2) Learn Data Science and modeling
Analyzing and modeling data is an excellent skill to have as a machine learning engineer. However, most ML engineers are not responsible for modeling data because they are in charge of model infrastructures like tracking, deployments, serving, and storage.
I think it’s important to know how data is cleaned, analyzed, and modeled. It might give context for building better APIs for data collection and how to design better databases. In addition, it is important to know about databases and SQL, as well as have experience working with data visualization tools. Some of the most popular frameworks for analyzing and modeling data are:
Pandas: Think of it as Excel for Python. Used to read data and perform rudimentary analysis.
Scikit-learn: A machine learning framework that contains almost all the popular algorithms.
Tensorflow/PyTorch: Deep learning frameworks used to train and build models.
Matplotlib: A Python framework for visualizing data and making plots.
3) Model Serving
Every model with utility needs to live somewhere on the internet for it to be accessed. For models to be easily incorporated into web and mobile apps, it’s best to serialize them as APIs that can be accessed via HTTP requests.
The best way to build APIs for these models and access them might depend on the type and use of the model, the process of doing this is called model serving or model deployment. Some of the best tools that are well-known in the ML circle are:
Seldon: An MLOps framework to package, deploy, monitor, and use machine learning models
TFServe: A framework designed to serve TensorFlow models on an HTTP API server.
Other notable frameworks used to make APIs for models are Kubeflow, BentoML, Flask, FastAPI, Django, etc. Building APIs for your models with tools like Django and FastAPI might be a lot of work for someone who doesn’t have a lot of software engineering background, which is why tools like Seldon exist to help you speed up this process in a very efficient way.
4) Model Versioning
So you’ve deployed your model. Now, what? It is essential to know that new data might keep coming in as your website or application is used, and you need to keep training your model with this new data. Of course, you don’t want to do away with your old models. You want to have somewhere to store them along with your new models. This is where model versioning comes in. In real-world machine learning, different models are built with selected features from the dataset, and they’re tested to see which can give the best performance. You always want an efficient way to store and version these models.
Data Version Control (DVC): A framework used to version control data and machine learning models.
MLflow: An open-source tool used to store, annotate, discover, and manage models in a central repository.
One closely related concept to model versioning is feature storage. Most times, when we process raw data and convert them to features for machine learning algorithms, we do not want to redo that process again given that the dataset might be big and it took a long time to process in the first place. This is where feature storage comes in.
Some tools give us the ability to store features, so we do not have to repeat data cleaning and feature engineering workflows.
One popular example is Feast, an open-source framework for feature storage. A novice mistake is to think that data and feature storage are the same, but they’re different in the sense that features are columns in datasets that have been cleaned or engineered for model training.
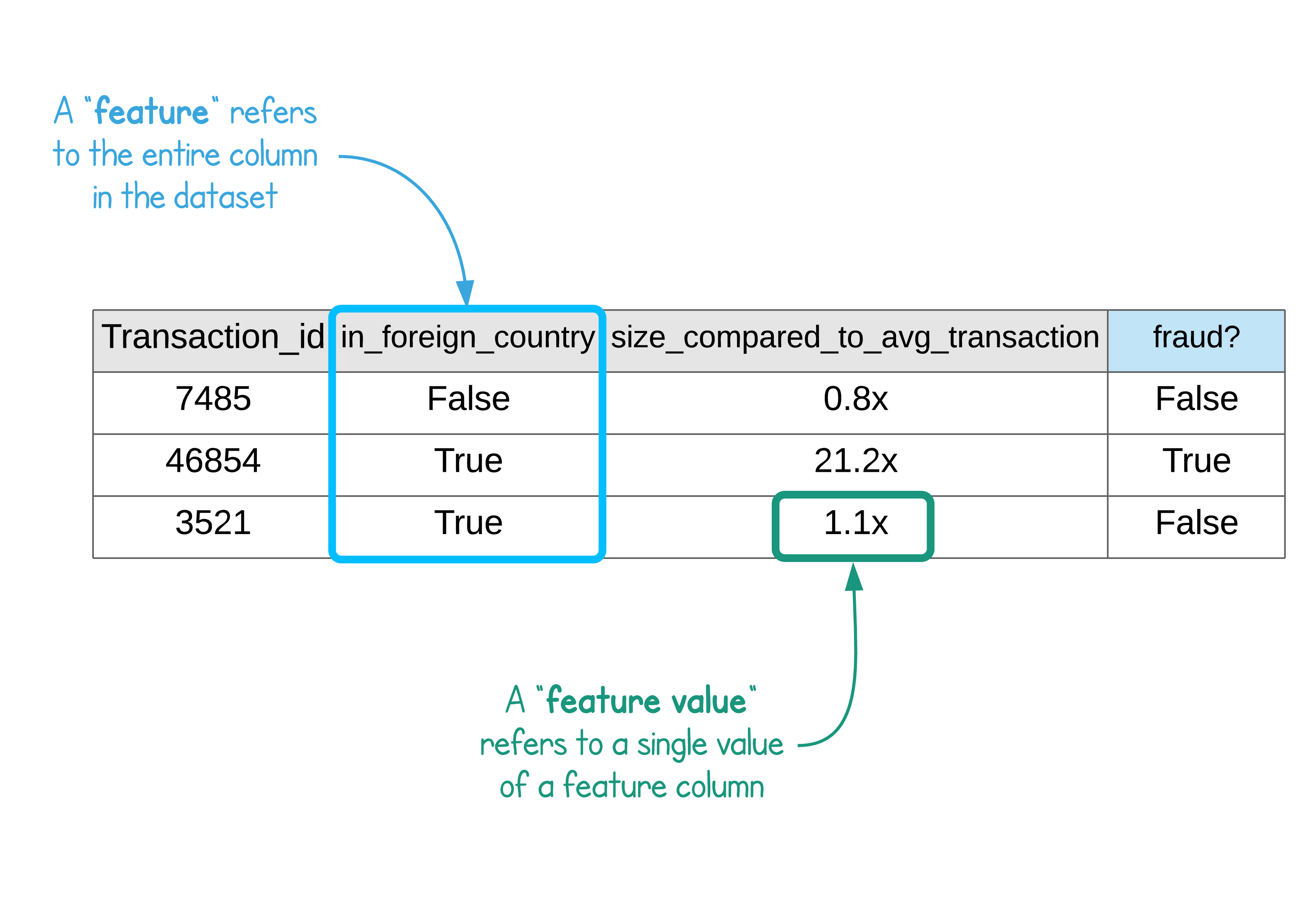 Image from https://feast.dev/blog/what-is-a-feature-store/
Image from https://feast.dev/blog/what-is-a-feature-store/
5) Model tracking and monitoring
There are a lot of moving parts in machine learning. You always want to keep track of them—performance metrics, model weights, hyperparameters, training logs, etc. Right now, there’s a running joke in the ML community that even with advanced tooling available, ML teams like to track their experiments on a shared Google Sheet.
While that might be done out of convenience, there are more efficient ways to track ML experiments. As I wrote earlier, a couple of things you might want to track are performance metrics and scores, hyperparameters, training configurations, and training logs.
It’s always great to track and store these things in an organized and easily searchable way. A lot of trial-and-error goes into tweaking model hyperparameters and configs before striking gold with the best model for your use case. This means that you might forget the best combination of hyperparameters or configurations that led to your model if they are not correctly tracked and monitored.
There are a couple of tools that market themselves as all-in-one MLOps kits. I’ve not used most of them because they are sometimes expensive proprietary software, but they might be ideal for teams looking for tools that are easier to set up and manage.
Some examples are AWS Sagemaker, Google Cloud AI, etc. Other free alternatives are MLFlow, TensorBoard, Flyte, MLrun, etc.
Now that we've talked about tools and skills to learn, it’s also important to note that machine learning is not just about training models. In fact, I think anyone with two brain cells can train models. Some things, like model evaluation, validation, and verification, are the major elements that’ll determine if a model will have any utility in real life.
You want to have well-defined metrics to measure how well your model is doing and if it’s working the way you intended. The way you’ll evaluate and validate your model is usually specific to the type of problem you’re trying to solve and the domain to which you’re applying ML methods. This is why software and ML engineers work hand-in-hand with domain experts. In general, it’s always good to be skeptical of any model that has not been properly tested and validated.
As a recap, the ML lifecycle starts with us asking if we can use ML to solve a particular problem:
- 1. We make the problem well-defined and try to find historical data that can enable us to train a model that’ll generalize to new or future data.
- 2. We train different models with different algorithms and feature sets to see what performs best.
- 3. We evaluate and validate this model to make sure that it works well above a certain threshold, say more than 80% of the time. You generally want to have a good way to measure how reliable your model is.
- 4. We serialize this model and deploy it as an HTTP API for mobile or web apps.
- 5. We keep track of the performance of this model after deployment to monitor if it still works as we intended and how well it does.
- 6. If there’s a large inflow of new data, we retain our models with this data and continue this cycle from step 2.